This is a technical post going into depth about the work i’ve done in the last sprint, if you’re looking for my general update you can check it out: here
If you’re not up to date and you’ve stumbled on this post through my shit posting everywhere You can see the previous posts:
Tech stuff can be dry at times, so I’ll add pictures, colours, maybe some explosions – keep it interesting.
I will also over explain so non-techies can understand better, it’ll still be very technical but at-least if you’re interested in learning it won’t be completely off limits!
Are you ready for some excitement?!?
Chat Client
This is the software that will run in your web browser, phone, toaster etc and connects to our chat servers, letting you talk shit and share memes all day 🙂
This sprint, my goal was to isolate the event handler from the core code to make it easier for a developer to extend it.
The event handler basically tells your browser / app / toaster how to react to events from the server. Eg if you receive a “message” should your browser
Show the message it to you, the user. or
Explode
An exploding message
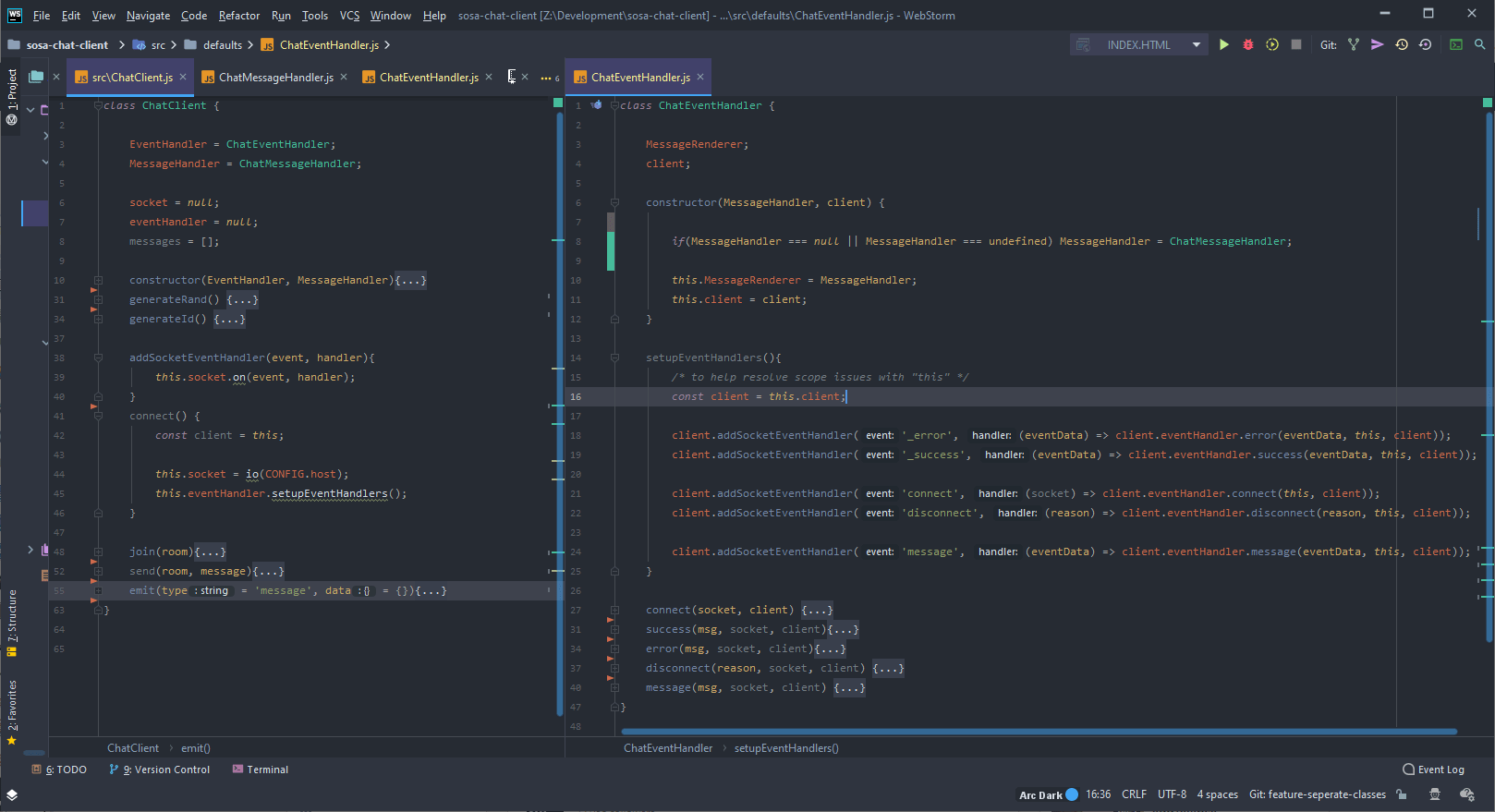
The biggest problem with trying to build a unified code base is that some implementations will need access to more events than others, so hard coding how events are handled the handler in the ChatClient class doesn’t make sense.
ChatEventHandler class handles events and the rest is hard coded in the ChatClient class.
A few languages support something called Reflection, this allows us to analyze how a class is implemented, this is commonly used to identify any annotations used in the code or expose available methods to another part of the codebase.
The original code
Using Reflection would allow future developers to focus on development and not how I’ve implemented things behind the scenes. Makes development quicker, easier to understand and easier to test.
Effectively abstracting the two and result in self documenting code.
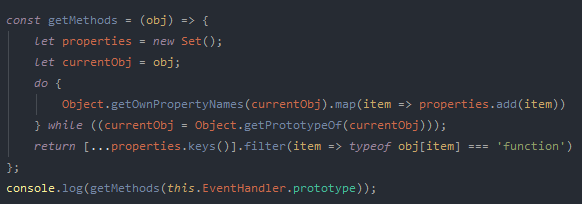
Having never tried to use reflection in Javascript, I didn’t know if it was viable. I know ES6, ES7 and so on have introduced some cool new features so I did some Googling and came across this: https://flaviocopes.com/how-to-list-object-methods-javascript
Get Methods Code
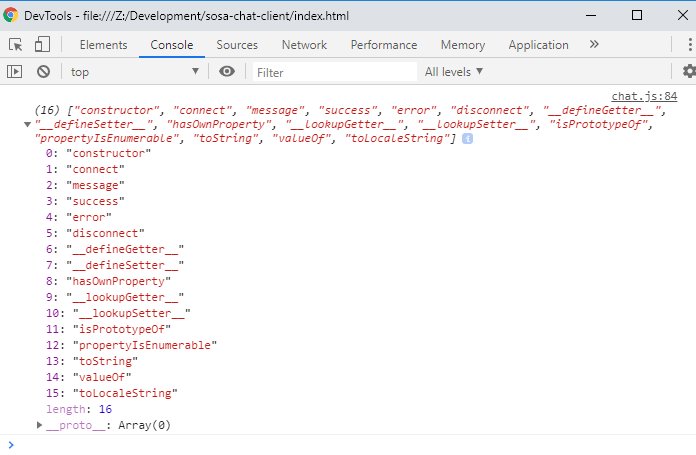
Not quite what I need! But would at-least allow me to all the methods on my classes prototype and then I should be able to use those to define my events.
ChatEventHandler prototype methods
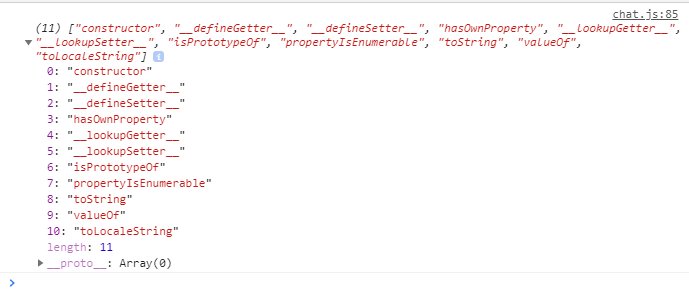
Unfortunately, when I implemented and ran it in Chrome, i got the prototype inherited from the Object class, which makes sense because everything extends that.
Object’s prototype!
With a slight change, I can get all of Object’s methods to and then remove these from my array so the result will be all the events I want to handle.
There was a huge flaw in my otherwise genius plan! … private methods.
Code needs to be readable and where possible self documenting, this makes it really easy for other developers to pick up in the future and can make it easier to find bugs.
When a method is too long, it can be hard to digest and the complexity gets lost, so i’ll typically break down long methods into smaller ones where appropriate or where i’m going to reuse code.
If I’m automatically getting all my event handlers just from the code with Javascript, I don’t know the difference between what should be an event and what should just be a helper!
That could have unintended consequences and as the code base grows could create some interesting bugs…
Hmmmph!
What I need are private or protected methods, classes were only introduced into Javascript in ES6 so I needed to do some research.
It does goes into a few ways to define “private” methods using javascript or at least limit methods scopes
Some really good ideas, but unless a developer uses them on a regular basis they won’t think to solve the problem in that way and instead will solve their problem using common solutions.
For our use case that means either hacky or bloated code especially in the long term.
To explain for non-devs, that’s like a car manufacturer suddenly swapping the gas and brake pedal in your car. You’ll get used to it sure – but you’ll probably crash before you do!
So Javascript is likely to get private and static methods but they’re still only a proposal, there is some limited support for it but it’s not standard and won’t be mainstream for a while yet!
What I did instead!
After a lot of head scratching and fucking about I decided to build the ChatEventHandler class in a way that it specifies what it can handle and how it handles them.
This means a bit more code for a developer but ultimately gives them full control and allows them to isolate the event handling from other business logic.
Pipelines / DevOps
Pipelines make it really easy for me as a developer to develop a feature, build it, test it, and know it’s production ready with minimal effort.
Jenkins was working in a previous sprint, but logging in or having it e-mail me every time it built is annoying and spammy so now it posts in my slack every time it builds.
This means every time I commit a change to Github, i’ll get a notification in Slack if it’s run properly, including any tests and later performance and security checks.
Jenkins nonsense
For the uninitiated…
Imagine you’re building a house of cards, every time you place a card it could be your last. The house of cards comes tumbling down!
A Pipeline is great because you can tell it where you want to place a card and it will test it out before I commit to it in real life!
If what i’m about to put live will bring everything crashing down, I know long before I do any damage.
Another great feature of pipelines is that if it’s clever enough, multiple people can add to the house of cards and we can see what cards fuck up our house and what cards work out!
This gives us the opportunity to fix the fuck ups.
Chat Server
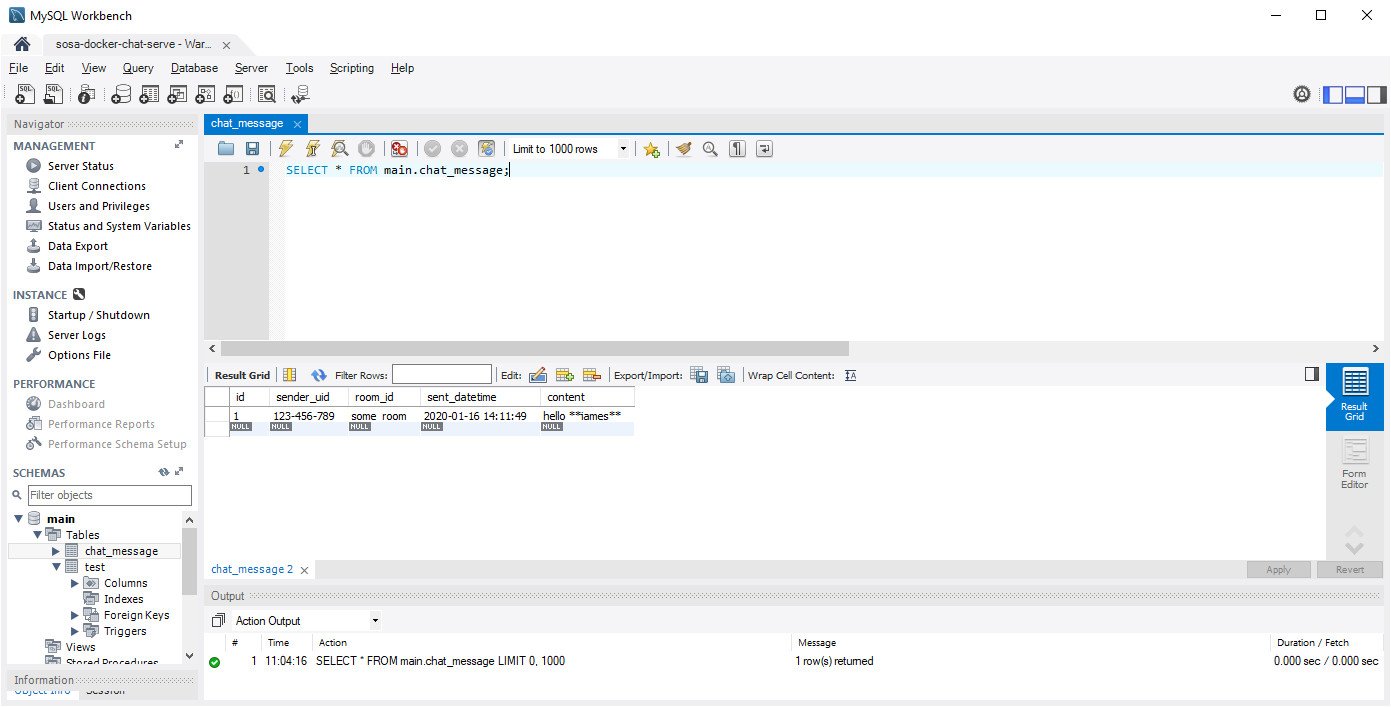
Next up, is connecting the chat server to the database!
This allows the chat server to maintain history, which means a user can see the last 50 messages when they join the room, or scroll until the end of time and life as we know it, finally putting an end to the pitiful human race once and for all.
Sorry I trailed off there for a moment…
I’m only 4 weeks in, so I’m not 100% sure what database/s i’ll be using and I don’t want to use a single database technology for everything.
Chat server Mysql Driver
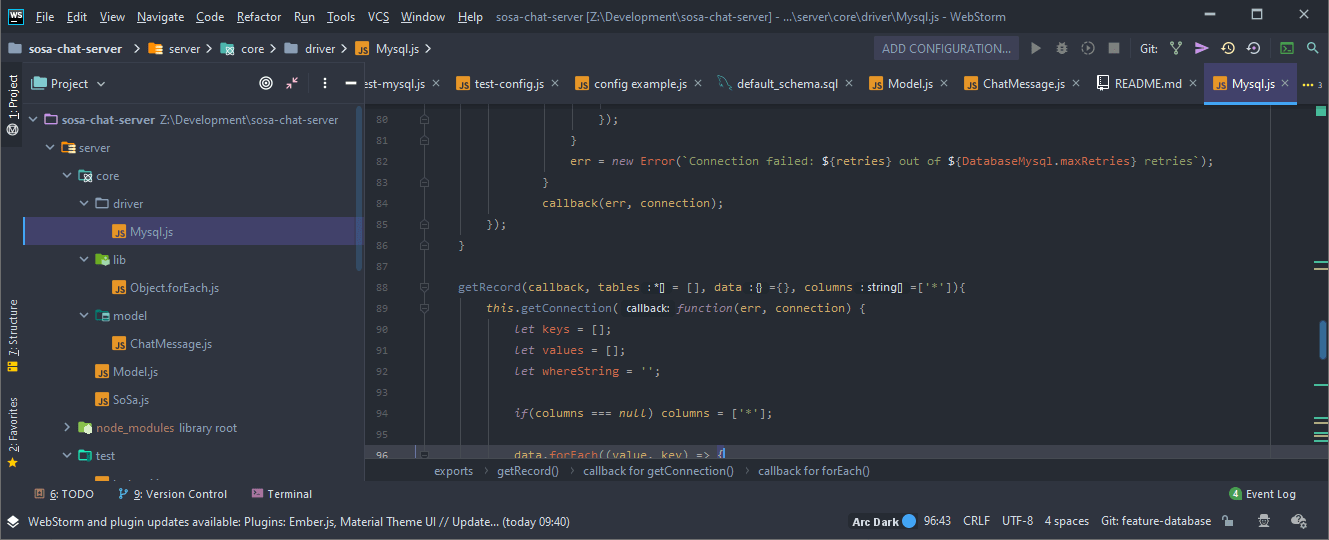
Initially, I think I’ll be using Mysql for cold storage allowing me to utilize replication and provide a more consistent way for other systems to easily analyze chat messages.
A NoSQL solution will probably be used for warm storage, this will allow me to quickly roll up isolated servers, for example if one part of the community is more active than the rest I can give it a dedicated instance and mean that it scales well without huge hardware costs.
Get driver code
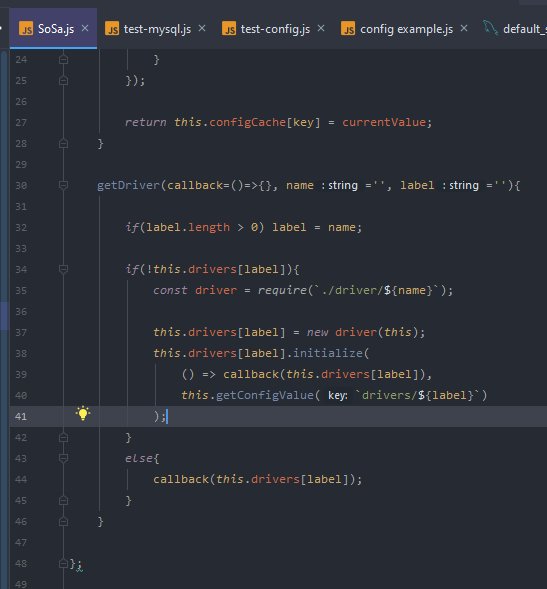
Everything is built using a model and driver concept.
A driver might be Mysql or MongoDB, which is initialized by a central controller class called “SoSa” and has some basic caching, which allows database instances to be used across models instead of per model.
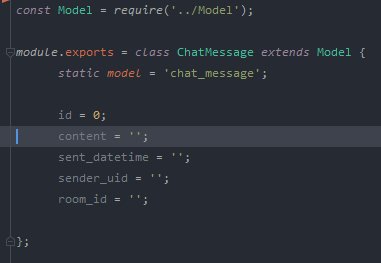
A Model then represents the underlying data model, they define where that data sits and can include methods to transform the data.
Model code
Example database the model is based on
This has all been built in a way that it’s really easy to test (i’ve built a bunch of unit tests to), extend and add layers of caching to the models.
Fun Fact:Chat rooms were a last minute addition to the original SoSa and turned out to be the reason people stuck around!
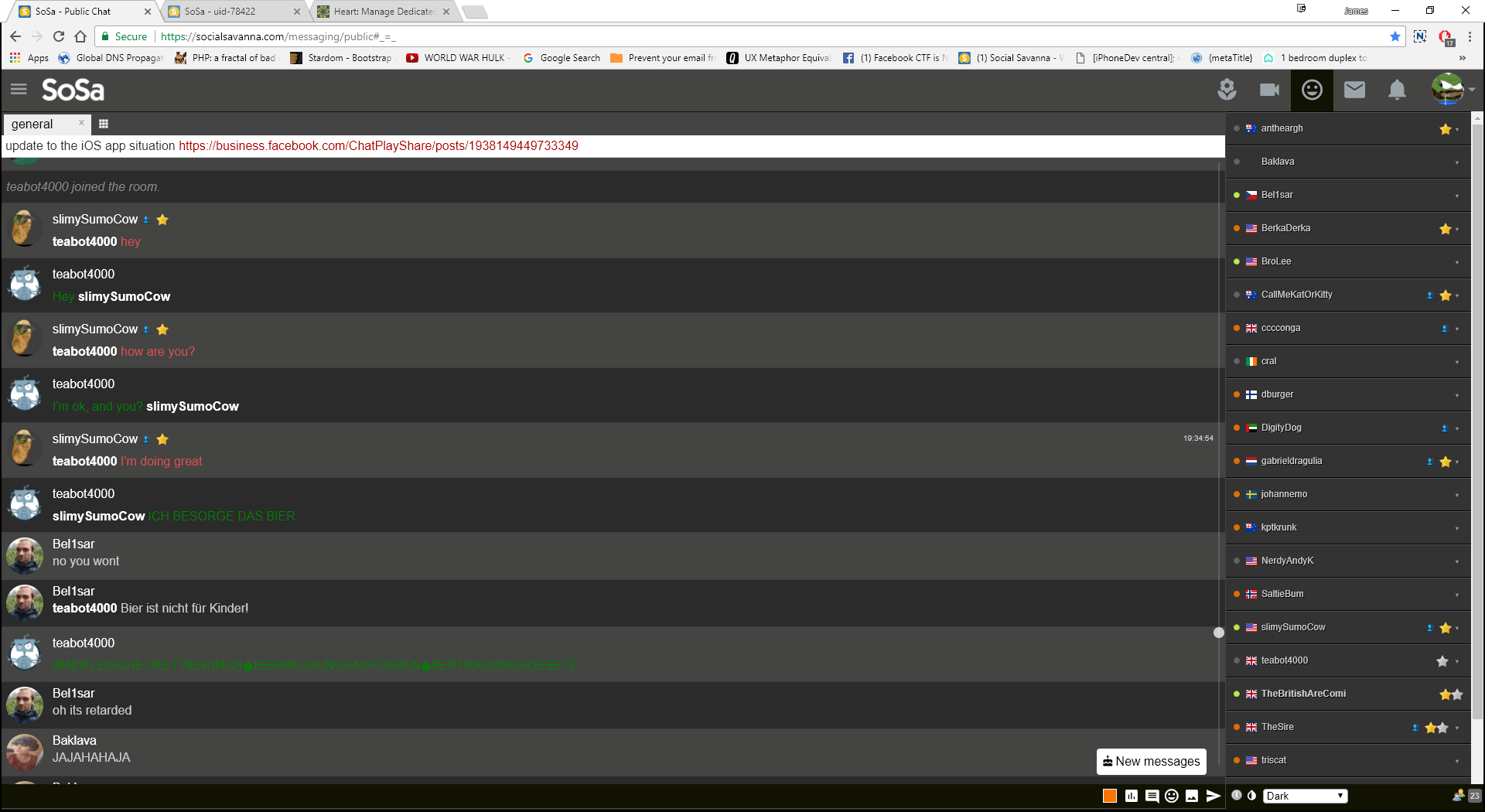
For the original SoSa, I used a piece of software called Openfire.
Openfire was really hard to work with and scale, things like embeds, emojis, message filtering, subscription colours, profile pictures and country flags I had to build a “hack” to make functionality work. I even had to build our own DM system because Openfire’s DM system just wasn’t up to the job.
Teabot4000 talking nonsense
Having a custom chat server, that’s easy to work with, well documented and eventually open source will really benefit the community and my sanity!
Anyway, that’s it for this sprint! I hope you got your fill and I’m looking forward to sharing my progress in the next two weeks again 🙂






 Become a patron
Become a patron
 Squid James
Squid James
 Guess who’s back, Back again!
Guess who’s back, Back again!
 Sprint 28 – a New Hope
Sprint 28 – a New Hope
 Sprint 2 – The ummm Foundations?
Sprint 2 – The ummm Foundations?
 Sprint 1 – The Foundations
Sprint 1 – The Foundations
 Precursor
Precursor



